This blogpost describes the Tokenlearn method, which is a method to pre-train Model2Vec models.
We’ve been brewing, concocting, distilling, and came up with a new distillation technique that leads to much better models, which we are now releasing under the name POTION. We open source all models, code, and data.
We’re releasing three versions: a 64-dim (1.9M params), 128-dim (3.8M params), and 256-dim (7.6M params) model, all based on the same base model, which is, in turn, a bge-base distillation. All POTION models outperform all previous distillations in their size class, and should be considered to be drop-in replacements of our M2V_base_output model. potion-base-8M, in particular, even improves over our largest model, M2V_base_glove. potion-base-8M is better than any set of static embeddings we could find on any task, including glove, fasttext and specialized word embeddings.
Get them here:
The Tokenlearn code can be found here.
The rest of the post will detail how we made the models, how they perform, and further improvements we have in store.
Distillation
In our regular model2vec framework we distill sentence transformers down to really fast tiny models by doing a forward pass for all tokens separately. We then perform Principal Component Analysis (PCA) on the resulting embeddings, and weigh the individual embeddings via Zipf’s law. See our previous blog post here. The new distillation framework is composed of 4 steps.
- Model2Vec distillation
- Sentence transformer inference
- Training
- Post-training regularization
These four steps take a bit longer than the previous distillation framework. If you are looking for a quick way to get a model2vec model, distillation is still your best bet. If you are looking for maximum performance, read on!
1. Distillation
We start from a distilled model. In our case, we are using the M2V_base_output model as our starting point.
2. Sentence transformer inference
We then go back to the original big sentence transformer, and use that transformer to create ~1M embeddings on an in-domain corpus, which for us is C4. We then throw away the sentence transformer, never to see it again. Forget it existed.
3. Training
So, we now have a base model, and 1M texts and 1M vector representations of those texts. We then train the base model to minimize the cosine distance between the representations it produces and the representations we produced before. In doing so, our model learns to better mimic representations made by a large model. We also add a super heavy regularization term to the produced embeddings.
During training, we apply a few standard methods to improve performance, such as reducing the learning rate on plateau, and early stopping.
4. Post-training re-regularization
Finally, after training, we re-regularize our models by performing PCA, and by manually re-weighting individual tokens.
Of note here is the manual re-weighting, which is very similar to the Zipf weighting we use, but now relies on external data. Before, we assumed that all tokens were in rank order, and simply weighted them as follows:
w = log(1 / rank)
This works really well, as shown in our original blog post. Using actual frequencies, however, works even better. We use the same 1M documents on which we trained, and collect token probabilities for all tokens in our vocabulary. We then reweight using the following formula from the SIF paper:
w = 1e-3 / (1e-3 + proba)
where proba is the probability of the token in the corpus. While this does mean our new distillation method relies on some data, it is worth it, as we will show below.
Results
Just like in our original experiments, we again evaluate on MTEB, as well as our two additional tasks (PEARL and WordSim). The results are shown in the table below.
| Model | Avg (All) | Avg (MTEB) | Class | Clust | PairClass | Rank | Ret | STS | Sum | Pearl | WordSim |
|---|---|---|---|---|---|---|---|---|---|---|---|
| all-MiniLM-L6-v2 | 56.08 | 56.09 | 62.62 | 41.94 | 82.37 | 58.04 | 41.95 | 78.90 | 30.81 | 60.83 | 49.91 |
| potion-base-8M | 50.54 | 50.03 | 64.44 | 32.93 | 76.62 | 49.73 | 31.71 | 73.24 | 29.28 | 53.54 | 50.75 |
| M2V_base_glove_subword | 49.06 | 46.69 | 61.27 | 30.03 | 74.71 | 49.15 | 27.16 | 69.09 | 30.08 | 56.82 | 57.99 |
| potion-base-4M | 48.87 | 48.23 | 62.19 | 31.47 | 75.37 | 48.75 | 29.11 | 72.19 | 28.89 | 52.55 | 49.21 |
| M2V_base_glove | 48.58 | 47.6 | 61.35 | 30.52 | 75.34 | 48.5 | 29.26 | 70.31 | 31.5 | 50.28 | 54.29 |
| M2V_base_output | 46.79 | 45.34 | 61.25 | 25.58 | 74.9 | 47.63 | 26.14 | 68.58 | 29.2 | 54.02 | 49.18 |
| potion-base-2M | 45.52 | 44.77 | 58.45 | 27.5 | 73.72 | 46.82 | 24.13 | 70.14 | 31.51 | 50.82 | 44.72 |
| GloVe_300d | 42.84 | 42.36 | 57.31 | 27.66 | 72.48 | 43.3 | 22.78 | 61.9 | 28.81 | 45.65 | 43.05 |
| BPEmb_50k_300d | 39.34 | 37.78 | 55.76 | 23.35 | 57.86 | 43.21 | 17.5 | 55.1 | 29.74 | 47.56 | 41.28 |
As can be seen, potion-base-8M is the best model we have released so far (surpassing the 50% average MTEB score mark!), further pushing the limits of what is possible with static word embeddings. Furthermore, the 4M and 2M models still work quite well, with the 2M model outperforming GloVE while being ~55 times smaller.
To show the relationship between the number of sentences per second and the average MTEB score, we plot the average MTEB score against sentences per second. The circle sizes correspond to the number of parameters in the models (larger = more parameters).
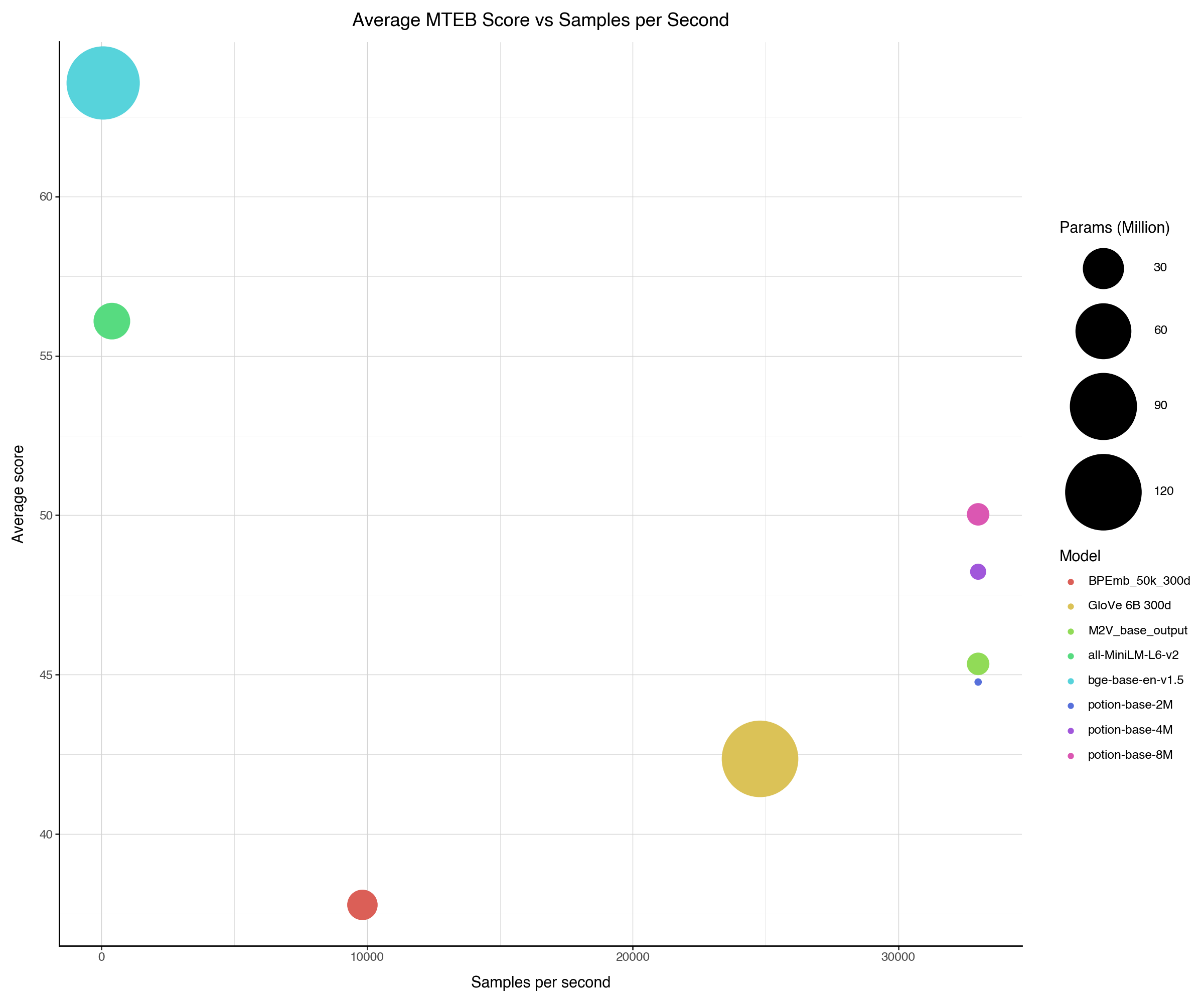 The average MTEB score plotted against sentences per second. The circle size indicates model size.
The average MTEB score plotted against sentences per second. The circle size indicates model size.